阅读笔记|Attention Is All You Need
warning: 这篇文章距离上次修改已过822天,其中的内容可能已经有所变动。
info: A. Vaswani et al., “Attention Is All You Need,” 2017, doi: 10.48550/ARXIV.1706.03762.
1.1 背景
- Transformer一开始主要针对NLP中的翻译任务
- 主流序列到序列模型通常基于复杂的RNN或CNN
- RNN由于结构特性存在并行性差的问题,且长记忆差
- CNN一次按一个窗口进行卷积,相距远的信息需要多重卷积才能融合
- 目前表现最好的模型包含编码器和解码器结构,并用注意力机制连接两者
1.2 主要贡献
- 提出Transformer,一个完全基于自注意力的新模型结构,区别于RNN或CNN
- 创新发展了注意力机制,提出多头注意力机制用于取代传统seq2seq中的递归层,兼具并行性同时有效建模了长距离依赖
- 将建模长距离依赖关系的操作的复杂度从RNN的线性和CNN的对数降至常数级别
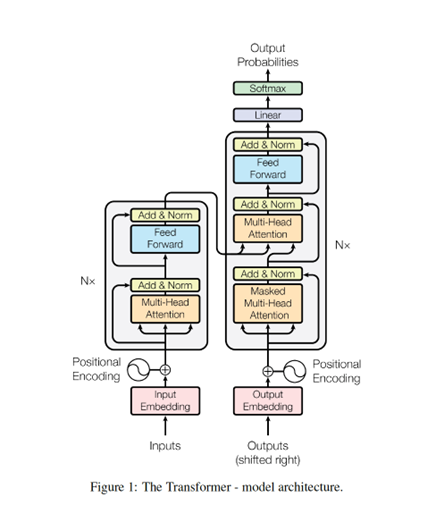
1.3 模型结构
整体架构
- 采用编码器-解码器结构
- 编码器和解码器都是N个相同的层叠加
编码器
- N=6个相同的层叠加
- 每层包含两部分
- 多头自注意力
- 全连接的前馈网络
- 每层后都有残差连接和层规范化
解码器
- 与编码器结构类似
- 在每个编码器层后面,添加一个多头自注意力用于编码器输出
- 自回归(前面的输出作为输入)
- 增加掩码机制,防止训练时由于自回归而提前看到后面的位置
Normalization
- BatchNorm:对于二维输入来说,对每列的同一特征进行normalization;三维输入中,依然是对于同一特征,不同batch和不同seq的数据进行normalization
- LayerNorm:对于二维输入来说,对每行的样本进行normalization;三维输入中,则是对于同一个batch,不同feature和不同seq的数据进行normalizationBatchNorm:对于二维输入来说,对每列的同一特征进行normalization;三维输入中,依然是对于同一特征,不同batch和不同seq的数据进行normalization
位置编码
- 因为没有RNN自带的时序结构,故输入添加正弦和余弦函数编码位置信息
自注意力
- Scaled Dot-Product Attention
- 将查询、键、值打包成矩阵,做缩放点积注意力
- 用参数dk控制缩放
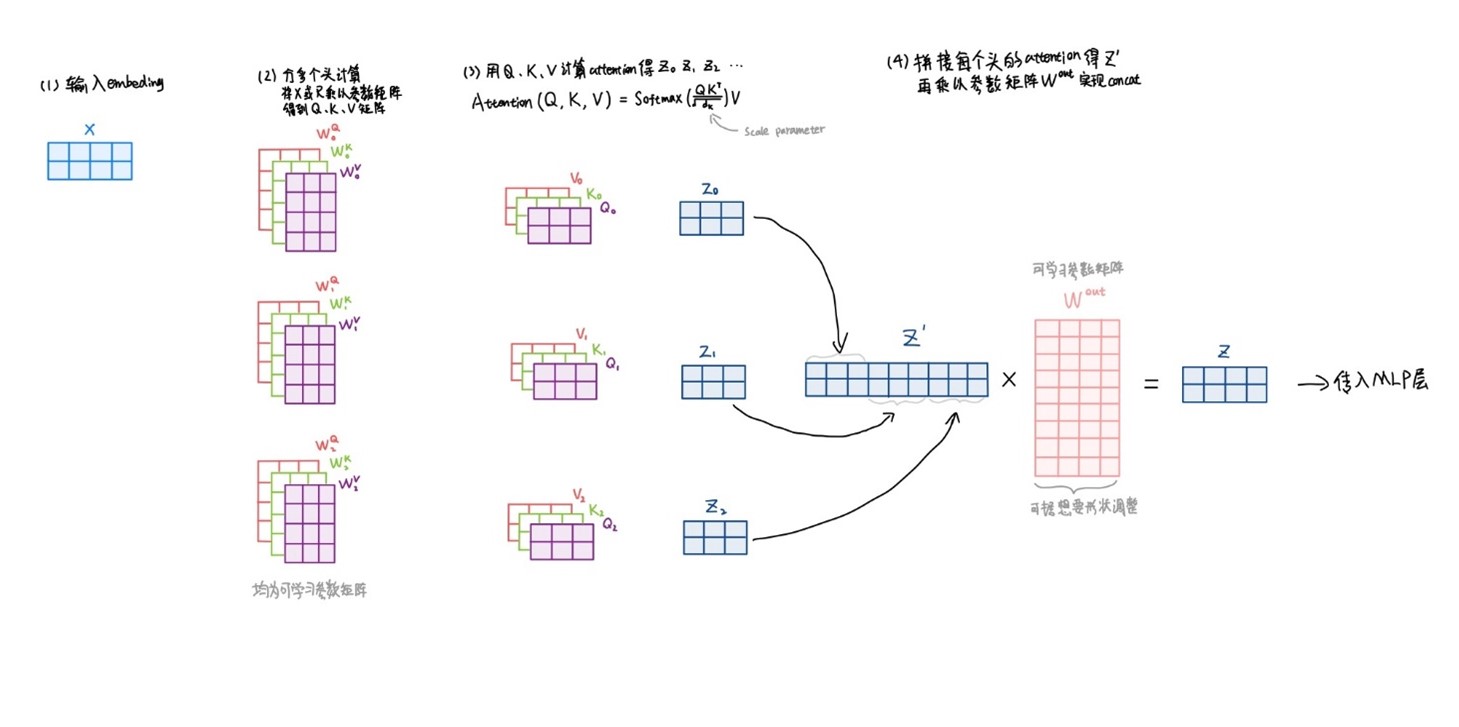
- Multi-Head Attention
- 将输入进行多次线性映射,得到多个头部
- 在每个头部单独做点积注意力
- 将所有头部连接起来做线性映射
- 允许注意不同的子空间
1.4 实验
训练
- 标准机器翻译数据集
- Adam优化器
- 标签平滑、残差dropout等正则化策略
结果
- 英德和英法翻译任务表现再创新高
- 英语短语结构分析也取得良好结果
1.5 个人思考
- Transformer并不是只要attention就行,MLP和残差连接等缺一不可,只是相对以前的seq2seq没有了CNN或RNN。
- Transformer的注意力机制没有像RNN那样在结构上去对序列做顺序上的建模,能处理更一般化的信息,能比CNN取得更好的效果,代价是需要更多数据和训练,模型越来越大。