阅读笔记 | AuTO: scaling deep reinforcement learning for datacenter-scale automatic traffic optimization
warning: 这篇文章距离上次修改已过907天,其中的内容可能已经有所变动。
info: Chen L , Lingys J , Chen K ,et al.AuTO: scaling deep reinforcement learning for datacenter-scale automatic traffic optimization[C]//the 2018 Conference of the ACM Special Interest Group.ACM, 2018.DOI:10.1145/3230543.3230551.
1.1 问题背景
在数据中心中,网络流量具有高度集中性、长尾分布性、突发性、时空异质性和大规模性等特征,数据中心的流量优化对网络及其承载的应用的性能有着显著的影响。目前,流量优化主要依赖于手工设计的启发式方法,这些方法相对并不完善,而传统的深度强化学习方法则由于较长的处理时间无法用于数据中心规模的在线决策。
1.2 要解决的问题
为了提高数据中心的流量优化效果并缩短优化过程的时间,本文致力于研究如何利用深度强化学习(DRL)技术实现自动化的数据中心流量优化,以适应庞大、不确定和多变的数据中心流量,解决时延问题,并达到操作员设定的目标。
1.3 现有方法的缺点
主要是针对手工设计的启发式方法其主要问题为:
- 线上自动适应不同的流量情况的能力缺失或较差。
- 周转时间较长,需要数周的时间进行设计和实施。
- 在参数与实际环境不匹配时性能可能会下降。
1.4 文章的主要工作
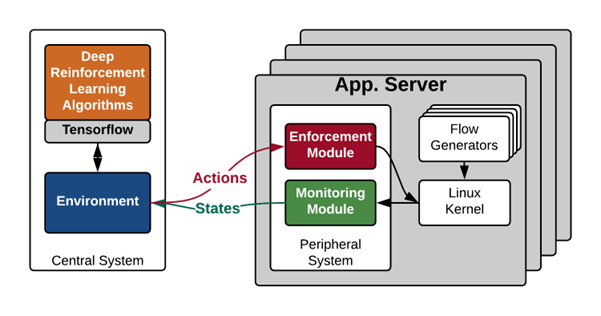
本文的主要工作是探索如何应用深度强化学习(DRL)技术解决数据中心流量优化问题。通过开发名为AuTO的两级DRL端到端系统,模仿动物的外周和中枢神经系统,并在外周系统引入多级反馈队列,再利用数据中心流量长尾分布,解决了数据中心流量优化中存在的可扩展性的问题,实现了对数据中心规模的流量级流量调度和负载均衡。文章最后还对AuTO进行了实现和小规模部署验证,并取得了符合预期的成效。
通过本文的研究和实现,研究人员展示了使用深度强化学习技术的自动化数据中心流量优化方法的潜力和效果,为提高数据中心性能和效率提供了新的解决方案。
1.5 个人思考
- 文章的方法非常巧妙,其中将AuTO分为外周和中枢两级的思想与上一篇阅读的《Interpreting Deep Learning-Based Networking Systems》中的本地和全局系统的划分有异曲同工之处。此文中外周系统运行在所有的端主机,作为local system收集流量信息并决策,同时接受中枢系统做出的全局决策。而中枢系统作为global system聚合全局信息并做出优化决策。但这之外,本文研究者还强调了一个关键点,也即中枢系统做出的全局决策是可以下发到外周系统并生效的。
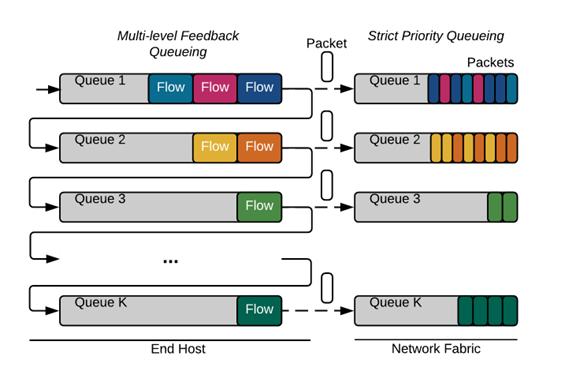
- 在AuTO的外周系统中,流量的控制调度采用了阈值控制的多级反馈队列,似乎和操作系统中的进程调度有些许关联,两者都是根据目标和调整策略进行动态调度调整。但在AuTO中,MLFQ更多根据流量的特征和源目的信息等上下文进行考虑。