阅读笔记 | CODA: Toward Automatically Identifying and Scheduling COflows in the DArk
warning: 这篇文章距离上次修改已过899天,其中的内容可能已经有所变动。
info: Zhang H , Chen L , Yi B ,et al.CODA: Toward Automatically Identifying and Scheduling Coflows in the Dark[C]//Conference on Acm Sigcomm Conference.ACM, 2016.DOI:10.1145/2934872.2934880.
1.1 问题背景
最近的一系列研究工作表明,利用coflows来利用应用层信息可以显著提高分布式数据并行应用程序的通信性能。但现有方案的无法实现coflows自动识别和调度。
1.2 要解决的问题
我们能否在不手动更新任何数据并行应用程序的情况下自动识别和调度coflows?这可以归结为三个关键设计目标有待解决:
- 对应用透明的coflows识别:我们必须能够在不修改应用程序的情况下识别coflows。
- 容错的coflows调度:coflows识别无法保证100%的准确性。coflows调度器必须对一些识别错误导致的错误输入具有鲁棒性。
- 可即时部署:解决方案必须与数据中心环境中的现有技术兼容。
1.3 现有方法的缺点
- 现有方法所基于的假设在多数情况下难以满足:即,所有在共享集群中的分布式数据并行应用程序(无论是平台即服务(PaaS)环境还是共享私有集群)都已经修改过,以正确使用相同的coflow API。在许多情况下,强制要求满足这个假设是不可行的。
- 应用程序和coflow API以及环境都有可能或经常变化,使得系统易出错,难实现。
1.4 文章的主要工作
主要提出了一个可在不修改应用程序的情况下实现自动快速准确识别和容错性调度coflows的算法CODA,并实现原型进行了小规模部署以及大规模仿真测试,结果符合预期。
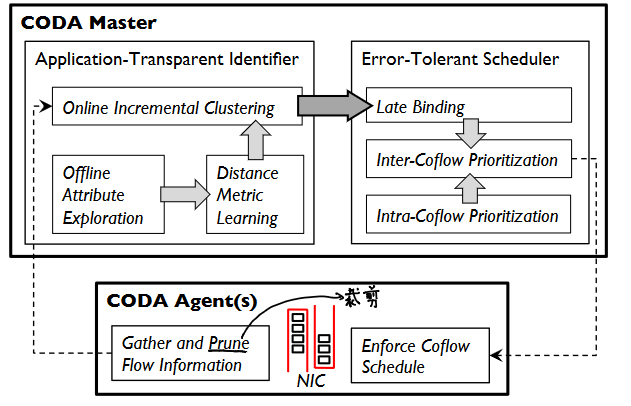
对应用层的透明性方面,研究者巧妙利用了基于DBSCAN密度聚类算法的incremental Rough-DBSCAN进行在线聚类,并辅以离线属性探索和距离度量学习,实现了快速准确的coflows识别,替代了之前研究提出的手工的侵入性的方式(比如在编写应用的时候通过注释),从而实现了自动地coflows识别。
容错性coflows调度方面,研究者分析了pioneers和stragglers两类误识别的影响并指出了stragglers对于CCT指标的显著的负面影响,针对此采用了延迟绑定最小化其影响。此外,研究者指出了coflow内部排序对于识别错误的关键影响,针对此采用了流内核流间优先级相结合的调度策略。最终容错性设计带来了CCT指标提升和错误影响的减少。
系统采取了主从架构,将流信息采集和coflow调度的执行交由代理机执行,流识别和调度决策由Master机执行,做了一个分离,实现了低性能损失下的高可伸缩性。
1.5 个人思考
- 系统采用了主从结构,但未明确提到其Master机是中心化的还是分布式的。但从其Discussion节对于CODA聚类识别的讨论中可以猜测其Master机是中心化的,因为其未实现并行的R-DBSCAN算法。我认为在大规模的数据中心中,主从结构可能带来性能瓶颈。但若是分布式的方案,又会增加复杂性。因此我想是否可以将相对耗时的聚类算法利用邦联学习的思想实现分布式学习,从而在各个agent完成学习或完成部分学习,提高整体性能。
- CODA的架构设计和SDN有一些相似之处,其agent只负责收集流信息和执行coflow调度策略,类似于SDN中的数据平面;而CODA的master机负责聚类识别和流调度决策指定,类似于SDN的网络控制平面。
1.6 延伸阅读
info: Chowdhury M , Stoica I .Coflow: a networking abstraction for cluster applications[C]//Acm Workshop on Hot Topics in Networks.ACM, 2012.DOI:10.1145/2390231.2390237.