阅读笔记 | Privacy vs. Efficiency: Achieving Both Through Adaptive Hierarchical Federated Learning
Summary
The paper argue that the efficiency and data privacy of Federated Learning are non-orthogonal from the perspective of model training, which means they are restricting each other. So that the paper strictly formulates the problem at first, and designs a cloud-edge-end hierarchical FL system with adaptive control algorithm embedding a two-level Differential Protection method to relieve both the resource and privacy concerns. The design follows the following ideas:
1.Offload part of the model training from resource-limited end devices to the proximate edges by splitting the model into two parts(shallow layers and deep layers) to improve efficiency.
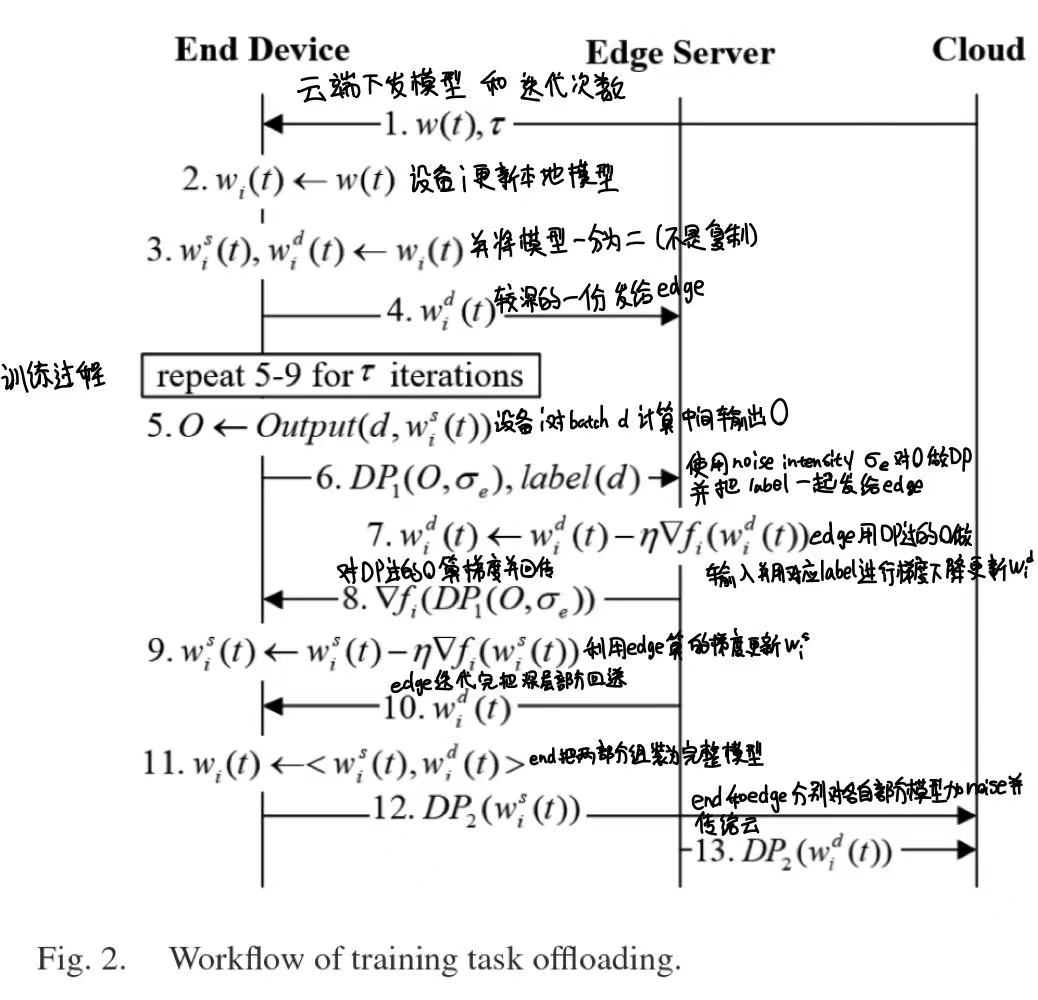
2.Apply two-level differential privacy (DP) noise injection to protect privacy against the honest-but-curious cloud and the edge server, perturbing model updates to cloud and intermediate features to edges. Specifically, the noise function between end and edge is $DP_1(O,\sigma_e)=O+N(0,S_f^2 \sigma_e^2)$, in which the function simply plus the intermediate features O of the end’s shallow layers and noise function N. For the cloud the DP function is $ DP_2(w_i^j)=\zeta \times w_i^j / \parallel w_i^j \parallel + N(0,\zeta^2 \sigma^2) $ , in which the model needs to be performed L2-normalization layer by layer.
3.Adaptively coordinate resource optimization and privacy protection to maximize accuracy under resource budget and privacy budgets. Main adaptive controls are:
- Dynamically schedule local and global aggregations based on resource consumption to minimize loss.
- Adjust device sampling rate based on remaining rounds and privacy risk to avoid early termination.
- Tune offloading decision and local noise intensity to minimize resource consumption since more noise make it harder to coverage.
A prototype of AHFL have been implemented and experiments are conducted on CIFAR-10 and MNIST, showing that AHFL reduces end's computation time by 8.58%, communication time by 59.35%, memory by 43.61% and improves accuracy by 6.34% over state-of-the-art approaches like ltAdap, FLGDP, FEEL.
Strengths
- Base on the assumption that security issues are worth concerning which is relatively less considered in some works.
- Offloading model training tasks by splitting the model into two parts while having a relatively comprehensive consideration on the privacy concerns between end device, edge server and cloud.
- Formulate the problem rigorously with math and UML diagram tools.
Weaknesses
- Balancing between iteration times and noise intensity may not be the optimal way because the model can be evaluated in many aspects and the iteration times only contributes to a part of it.
- Does not evaluate the effect of splitting method at the end device because different splitting may cause different computation and influence the offloading.
- The evaluation on CIFAR-10 and MNIST datasets are relatively simple which make it less convincing.
Comments
The paper mainly focus on privacy and efficiency in a federated learning system and design a hierarchical architecture with adaptive algorithms for balancing. Although the experiments are relatively not that convincing and some key details are not introduced, it’s still a innovative work. Besides, the figure 2 impress me a lot for using a UML lane diagram combining formula to precisely illustrate the workflow.